
(Editor’s note: This proposed solution to identifying hidden malware was first presented at Black Hat USA 2020 and is featured in the newly published report, The Modern Cybersecurity Landscape: Scaling for Threats in Motion. Download your copy here.)
As malware and spam become more automated and complex, cybersecurity professionals need new tricks to spot the malware and exfiltration of stolen data that can be hiding in images (steganography) and other files. One tool that could help them spot the hidden threats would be the use of “word entropy,” assisted by machine learning.
The basic concept behind word entropy is that the more complex malware gets, the less ordered, or efficient in its use of characters, that the file hiding malware becomes. This loss of order leads to entropy values that are much higher than would otherwise be expected — off-the-charts complexity that sticks out like a sore thumb.
Unfortunately, hiding malware inside image files makes it very difficult to remediate. Blocking common image file types would disrupt the entire Internet, to say the least.
There have been several studies on how entropy calculation can be conducted to determine whether a file is packed or encrypted using entropy. The same could be applied to image files. One way to do so is to look for randomness or noisy data in EXIF header or image trailers. This is where “word entropy” could help.
Using Shannon’s entropy theory (which quantifies the amount of information contained in a variable), Python scripts, and some logic tweaking, a solution could be developed to take advantage of this phenomenon. By applying machine learning to historical data records — system information, file URLs, passwords, etc. — automation could make it easier to flag the more anomalous files for further investigation. Working against a database of normal entropy values, threat researchers and incident response teams could then quickly identify those files where suspicious data transfer was occurring.
It’s actually possible to figure out if such complex malware exhibits behaviors that suggest it’s part of the same campaign or may be dropped by the same actor. The trick is to look for something called an “instruction or string similarity.” Every file in Windows makes use of the Windows API, executes call-backs during run time, or is linked to another file, ready to be used. Based on these calling conventions, one can figure out what the file might do and which family of malware follows this pattern.
A solid example could be a file trying to create a process, create a thread, suspend and resume a thread that could be flagged for process injection. With historic data of threats and these techniques one can categorize the file malicious, which family it belongs to, and even which actor follows the style.
As an example, we examined some compromised WordPress sites being used to host malware. The malware is used to infect a PC and steal data. Rather than call attention to itself by normal exfiltration through HTTP/S protocols, the malware employs steganography to hide the transfer of configuration data, operating system information, and more.
This is done using some interesting data hiding in plain sight in the EXIF headers of the file’s metadata. Not only is the data out of place, it looks like it might be javascript eval statements. Phone numbers, passwords, and other sensitive information stolen from victims computer could also be embedded inside EXIF headers and could be exfiltrated in a super stealthy manner. Further analysis shows a search-and-replace function that exfiltrates phone numbers and system data via callbacks to a command-and-control server. Searching and replacing by itself isn’t something that would be flagged, which is why even some sandboxes will miss the threat. It is this multilayered approach to obfuscation that makes these new forms of malware attack so effective.
Take a look at the image below:
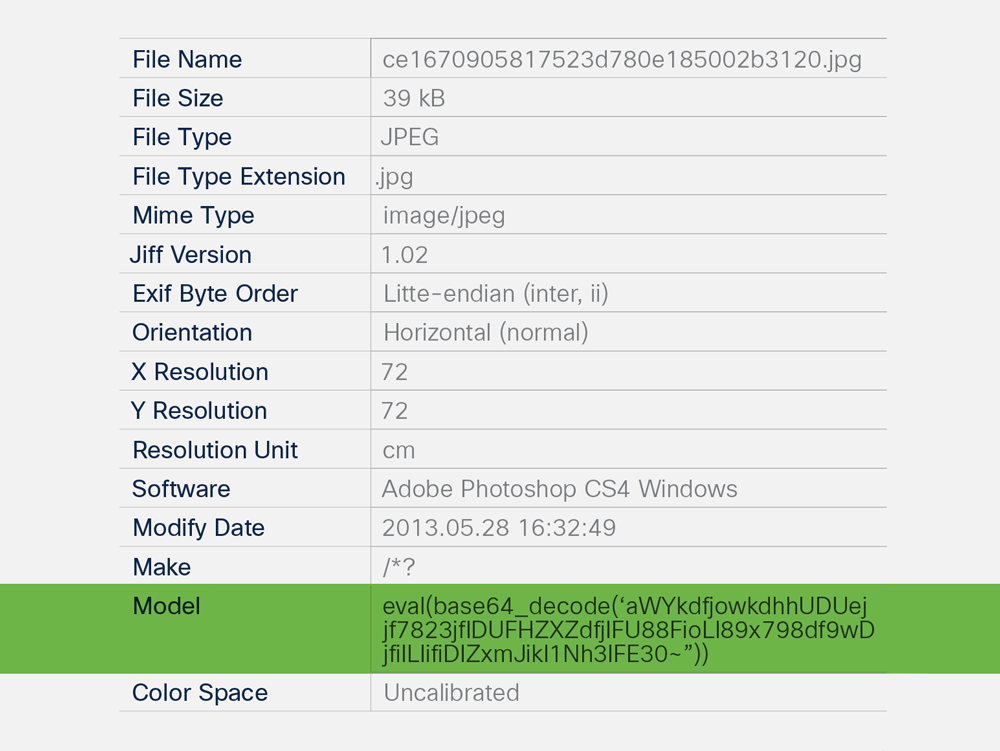
A sample section of metadata in an image file. The entropy analysis is focusing on the abnormally long “Model” information, highlighted in green.
Here we see that the model number has Base64 malicious code embedded in it. Word entropy can be calculated for EXIF header values, image attribute values, and other key attributes. If we calculate word entropy for each of the attributes present in the metadata, we’ll derive a base and a threshold score. Then, if we calculate the entropy score for the “Model” value, we’ll see that it exceeds the threshold score and stands out as suspicious.
Entropy alone cannot be a game changer in the detection of malware. Entropy has to be paired with other attributes to give an effective rating if the file is good, bad or ugly. The rise of machine learning implementation paves the way for such innovations and advanced detection methods. Instruction-seeking call patterns, string similarities when combined with attributes like mutex similarities, and variable naming patterns inside the code could give away a lot of information on which actor is engaging the malware and what similarities these samples have in common. Another trend in malware analysis is visualizing malware in grey-scale image and doing classification. This is rapidly gaining importance and is touted to tackle zero days with a good degree of accuracy.
Developing a database of the normal range of entropy values for image files would help threat researchers and incident response teams in more quickly identifying those files where suspicious data transfer was occurring.
Get your copy of the newly published report:
The Modern Cybersecurity Landscape: Scaling for Threats in Motion.